How to implement document automation in your business with Microsoft Power Platform



Thanks to automation solutions and AI, organizations can accelerate and optimize the processing of documents so humans can be freed from performing repetitive, low value and error prone tasks. This applies to any kind of printed or digital form like account payable invoices, delivery orders, receipts, and more.
Microsoft Power Platform offers to extract data from any kind of document (see Improve business performance with AI Builder) and a reference document automation pipeline (see Get started with AI Builder document automation).
Implementing such a solution is usually an iterative journey which could be summarized in 4 phases :
1. Building the initial AI model
2. Prototyping
3. Initial rollout in production
4. Mature production
Build the initial AI model
During this phase, a champion (commonly named as “maker”) with some technical background, will train an AI model using samples from the most common documents received to assess wherever the AI technology is able to properly extract data from these samples.
Select samples
To start, the maker should gather at least 5 sample documents for each document layout to process. The AI model will use these samples to learn how to extract the desired data. Usually, documents coming from different suppliers have different layouts.
The form processing model currently supports up to 200 collections which should in theory handle up to 200 suppliers. Given that there is a limited number of documents generating software, it’s likely that several suppliers will provide similar layout which could be extracted by the same collection.
This will be fine-tuned during the prototyping and initial production phase (see Prototyping section in this article ).

For each provider sample, the maker will identify which fields data and which table data must be extracted by the AI model.

Use the training wizard
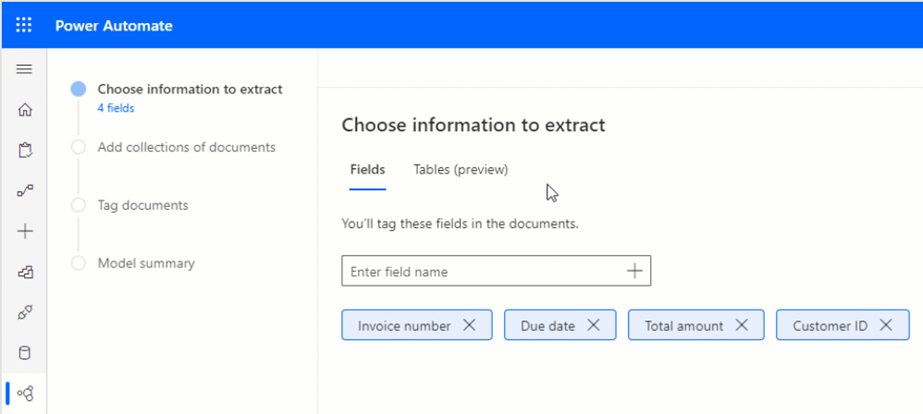
Now that the maker has gathered sample documents and has identified the fields and tables to extract, the next action is to create a new Form Processing model (see Create a form processing model). The first step of the training wizard is to define the fields to define in the “Fields” tab:
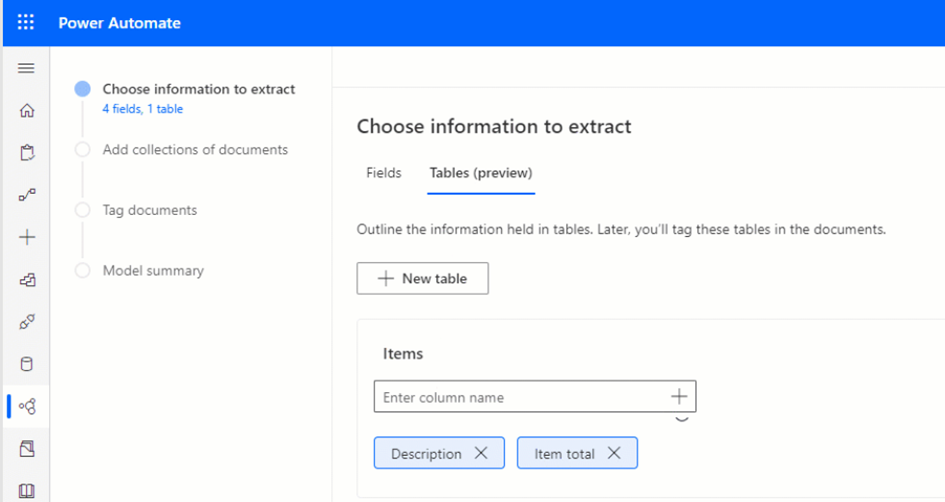
And the tables in the “Tables (preview)” tab
The maker will define one collection per layout, so one per supplier.
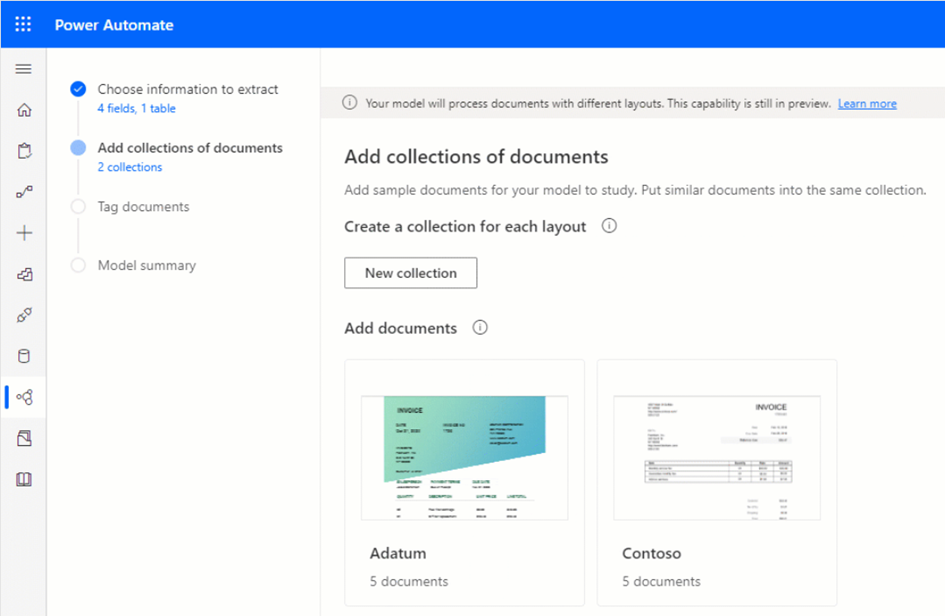
The combined file size of the documents used for training per collection must not exceed 50 megabytes (MB), and PDF documents shouldn’t have more than 500 pages (see Requirements and limitations).
Test the model
After going through the model tagging and training, the model is ready to be tested. The maker will use the “Quick test” to check that the data is properly extracted.
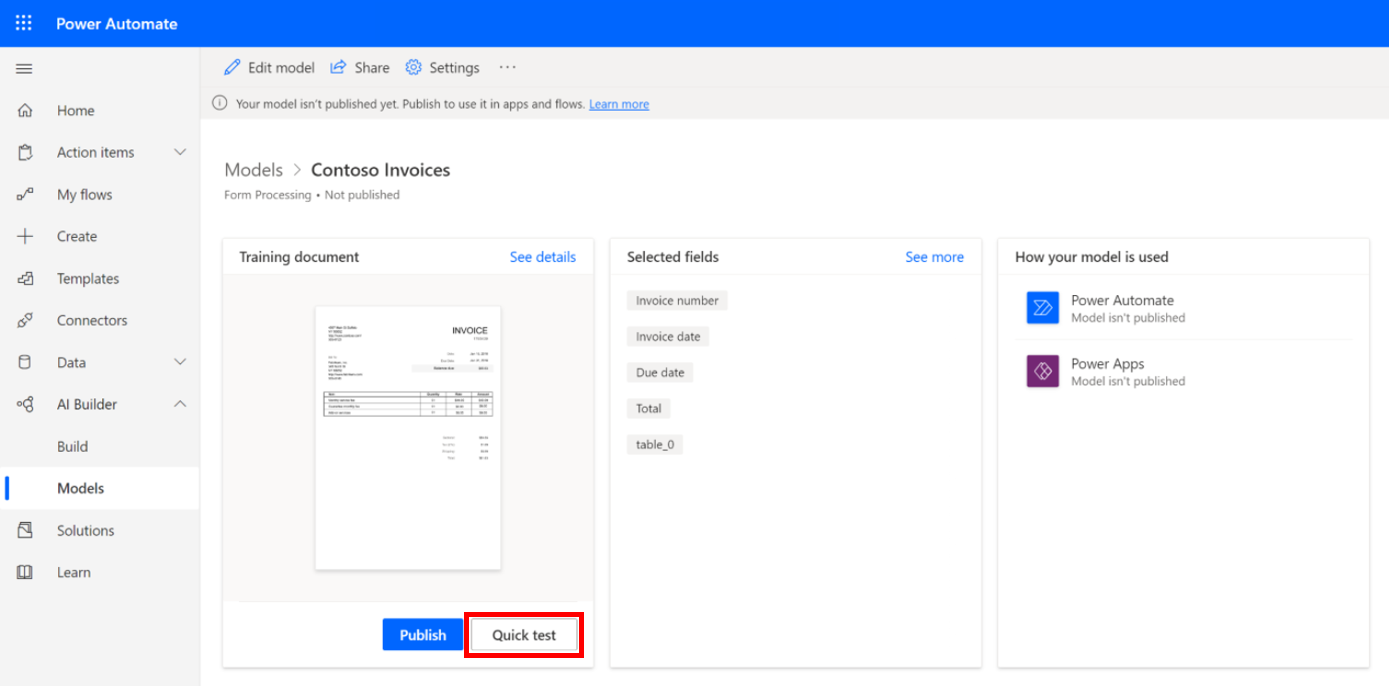
When necessary, the maker will use the “Edit model” to improve the performance by providing more samples or retagging (see Improve the performance of your form processing model).
Once satisfied, the maker can publish the model (see Train and publish your form processing model) and is now ready to step into prototyping.
Prototyping
During this phase, the maker will setup the document automation pipeline to adapt it to his business needs and will test it with selected documents.
The maker will setup the pipeline provided with Power Automate document automation base kit by configuring the previously created model to handle new documents received (see Configure the document automation base kit).
The result of the extraction is stored in Dataverse (see What is Microsoft Dataverse?) and manually reviewed in the document automation application by the maker.
This data can be manually imported to the target system or the maker can build an export flow.
The state of all documents entering the pipeline can be monitored in the document automation application.
- When the data is not properly extracted because of a specific layout, the maker can manually fill or fix the missing parts, then download the document to retrain the model manually and improve the accuracy for further processing.
- When the format of the document is not supported, the maker can take further actions like contacting the supplier or adding some conversion steps in the attachment extraction flow.
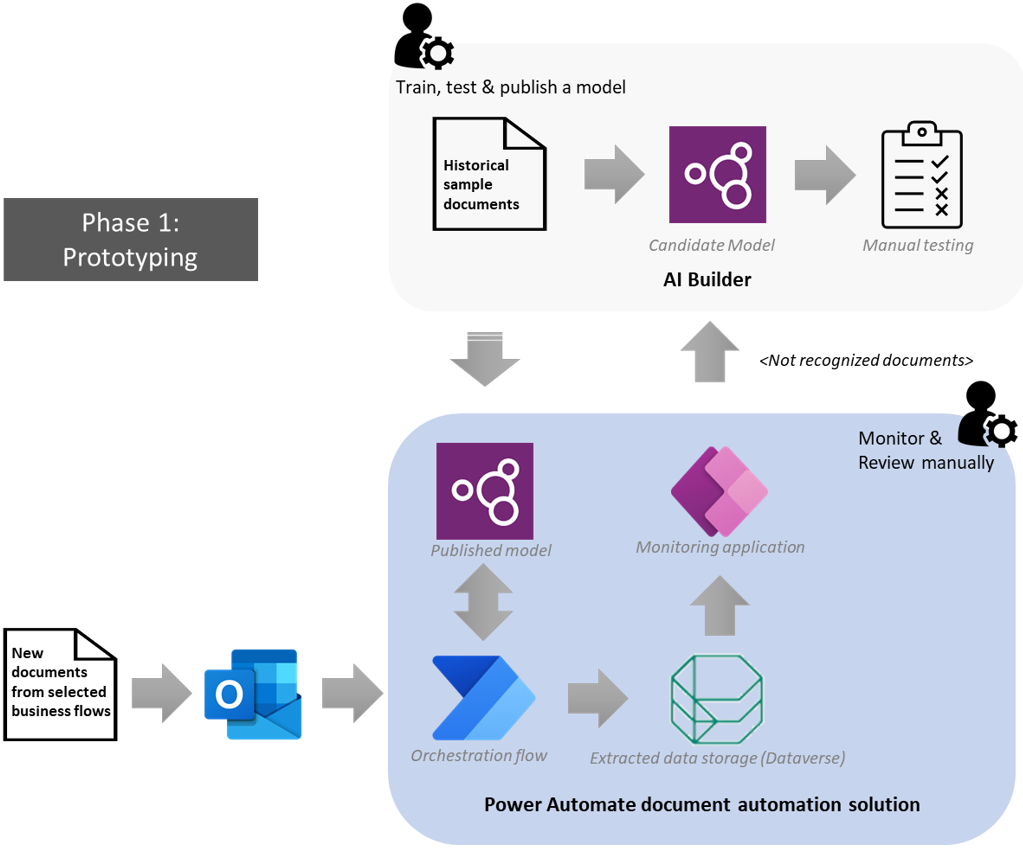
At this stage, the process continues to include a large part of human intervention as the organization needs to gain trust in AI to manage the sensitive business processes. The maker is playing a critical role fine-tuning the pipeline to fit with the organization’s needs.
Initial rollout in production
During this phase, the organization has confirmed that the solution is able to automate the processing of the documents and can expect significant productivity gains. The prototype will be rolled out to production for selected business scenarios during an observation period.
The model should have been optimized during the prototyping phase and should handle input documents properly in most cases.
The maker will implement in Power Automate some automatic validation rules after the data extraction to check if the data has been properly extracted. Examples of some validation rules include checking the model confidence, that all fields are filled in, and performing data consistency lookup on the target system.
The maker will also build a Power Automate flow to export the result of the extraction to the target system (CRM, ERP, or other) that will be triggered when the processed documents are validated.
If the data didn’t pass the automatic validation, it will be reviewed, edited, and validated in the document automation application like during the prototyping phase. This will happen when a supplier has changed the layout of the documents or a new supplier with unknown document layout has been added.
The maker will manually update and retrain the model to address these cases and ensure an automatic extraction in further processing. In the meantime, documents received from this new supplier will be manually handled in the document automation application.
Eventually, the business user will see documents flowing in the target system after the data export flow has been triggered and will be able to approve it.
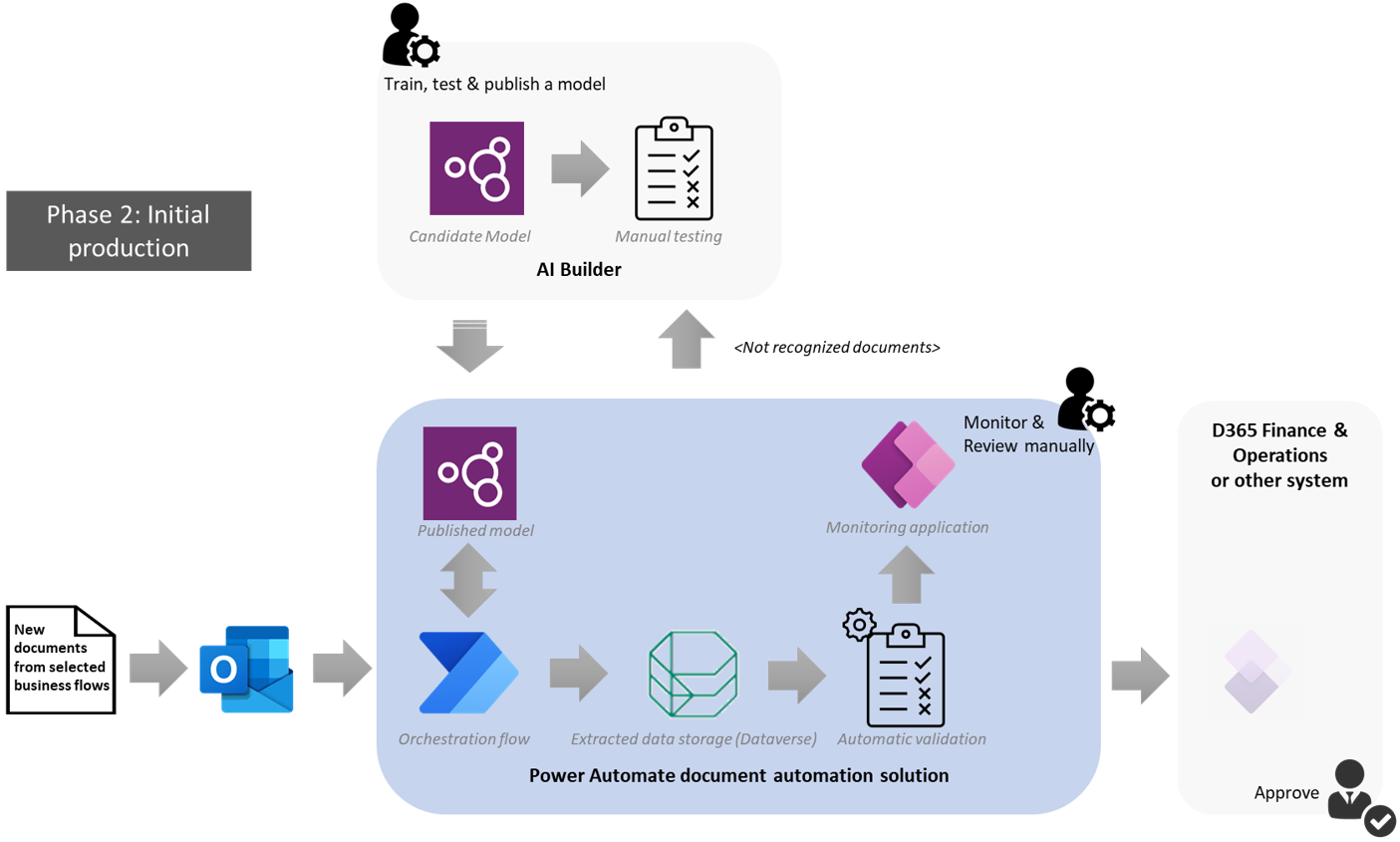
NOTE: The export to target system in the above diagram is not delivered with the built-in document automation pipeline. Each customer can easily customize it with Power Automate using one of the prebuilt connectors.
At this stage, the process is mostly automated but requires the expertise of the maker who performed the implementation to adapt to supplier’s changes and to manually handle corner cases.
Mature production
This is a phase that the organization will reach after months of productive usage. They will have defined the processes for the governance of this pipeline. This includes training manual reviewers who will replace the maker in managing rare cases where documents have not been properly extracted, and a process administrator who will ensure the efficiency of the pipeline.
Manual reviewers will be trained to review, edit, and manually validate documents that didn’t pass the automatic validation rules. In this process, they will tag these documents by drawing bounding boxes like what is done in the model authoring phase.
The pipeline will be able to handle this input to automatically retrain the model, improving the accuracy for existing suppliers, addressing layout changes, and supporting new suppliers.
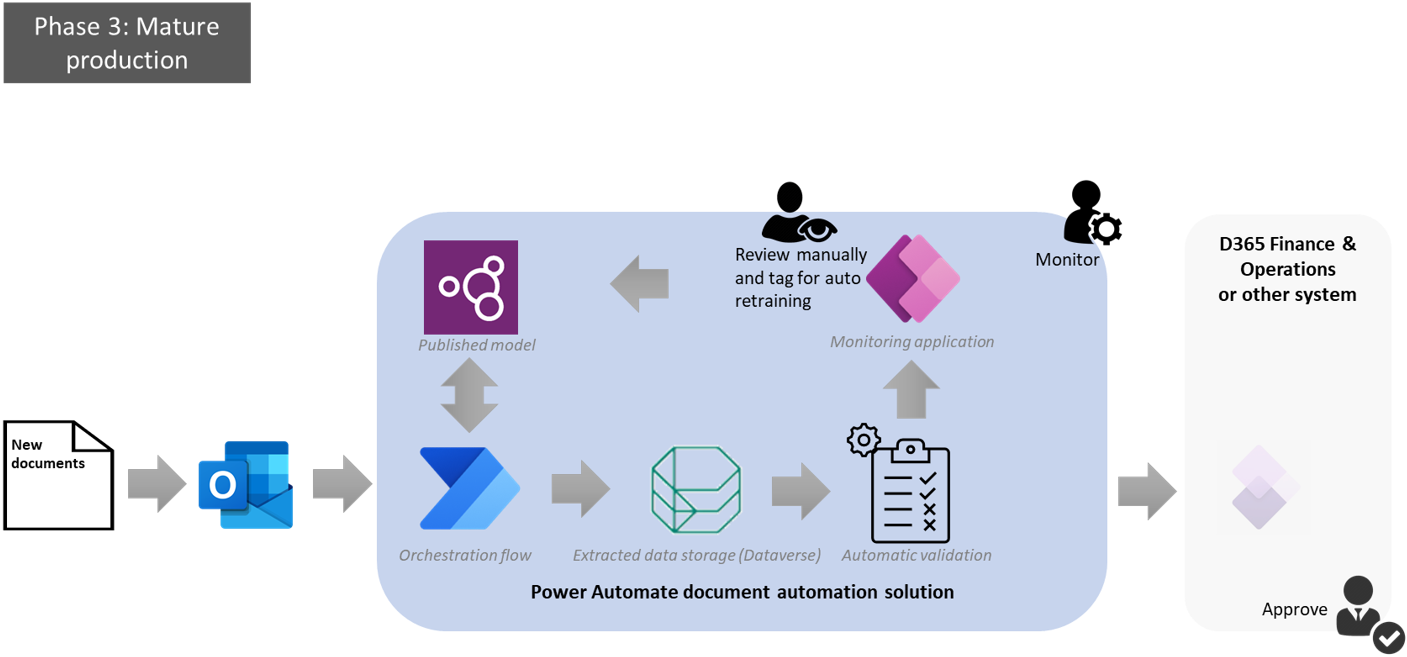
NOTE: Defining data validation rules and having an automatic retraining logic is not yet implemented in the current version of document automation. This is part of the roadmap and should be available soon.
At this stage, the pipeline will maximize productivity gains by removing most of the need for human involvement in the process. Manual reviewers will rarely review documents thanks to the automatic retraining that will ensure an optimal accuracy of the model. The process administrator will be in a monitoring perspective only acting in case of outages.
If you have any feedback or questions about document automation, feel free to share it with us in the AI Builder forum or email us directly at mailto:aihelpen@microsoft.com.